Program för att lösa Sudoku
 Har funderat på att bygga ett program som löser Sudoku-pussel automatiskt ett tag nu. En simpel algoritm är följande:
Har funderat på att bygga ett program som löser Sudoku-pussel automatiskt ett tag nu. En simpel algoritm är följande:- Upprepa följande, så länge det finns någon tom ruta i pusslet:
- Leta upp en ruta, som har precis en "kandidatsiffra"
- Fyll i rutan med kandidaten
I Pseudokod skulle de kunna se ut något sånt här:
sudoku = GetInputSudoku()
GreedySolver(sudoku)
print sudoku
function GreedySolver(sudoku)
__do
____pos = FindCandidatePos(sudoku)
____if pos!=null
______sudoku.Set(pos, sudoku.FindCandidates(pos)[0])
__while pos!=null
function FindCadidatePos(sudoku)
__foreach(pos in sudoku)
____cands = sudoku.FindCandidates(pos)
____if(cands.Count == 1)
______return pos
__return null
Läs även andra bloggares åsikter om programmering, sudoku, tdd
Regex i C#
 Den allra mest användbara metoden för reguljära uttryck i C# är nog Regex.IsMatch():
Den allra mest användbara metoden för reguljära uttryck i C# är nog Regex.IsMatch():string input = "olof";Observera att match betyder "återfinns någonstans i strängen".
string pattern = "of";
if(Regex.IsMatch(input, pattern))
MessageBox.Show("Found match!");
Läs även andra bloggares åsikter om regex, csharp, programmering, tips
Stora projekt, en reflektion

Så sant, så sant ...
Testa vad?
 Här är ett litet "tyckande" från mig, när det gäller TDD. I traditionell enhetstestning, uppmuntras man att ringa in "corner cases" eller "edge cases". Jag tycker att långt viktigare än dessa "specialfall" är de vanligaste fallen. Dessa bör det skrivas test för först av allt! När man skriver dessa enkla, vardagliga test, och implementerar kod för dem, kommer man att "se" corner cases i implementationen, och kan lägga till test/kod för dessa efter "vardagstesten". Så ska det vara!
Här är ett litet "tyckande" från mig, när det gäller TDD. I traditionell enhetstestning, uppmuntras man att ringa in "corner cases" eller "edge cases". Jag tycker att långt viktigare än dessa "specialfall" är de vanligaste fallen. Dessa bör det skrivas test för först av allt! När man skriver dessa enkla, vardagliga test, och implementerar kod för dem, kommer man att "se" corner cases i implementationen, och kan lägga till test/kod för dessa efter "vardagstesten". Så ska det vara!Läs även andra bloggares åsikter om tdd, programmering, rant
Testning av geometriska konstruktioner
 Satt och fick huvudvärk på jobbet nyss. Försökte testa algoritmer för att generera en viss typ av geometrisk data; inte klassiska Circle(), Point() och Line() utan mer specialinriktat än så (maskinstyrning om du nu måste veta).
Satt och fick huvudvärk på jobbet nyss. Försökte testa algoritmer för att generera en viss typ av geometrisk data; inte klassiska Circle(), Point() och Line() utan mer specialinriktat än så (maskinstyrning om du nu måste veta).I alla fall; eftersom jag är den ende utvecklaren med TDD-inriktning på jobbet, är koden ibland svår att testa.
I detta fall var det jobbigt att kontrollera om genererad geometri stämde överrens med förväntningar eftersom inte en enda av c:a 15 klasser implementerade Equals() - och referenslikhet räcker inte långt då man gör enhetstester av instanser som är lika i matematisk mening (samma "värde").
- Alternativ ett: implementera Equals() och GetHashCode() på alla klasser. Huvudvärk! Av flera skäl:
- Det är bökigt att få rätt på Equals() i C# (det finns hur många trådar som helst som behandlar detta på nätet)
- Det stökar ned de i övrigt ganska atomära klasserna jag ville testa
- Övriga utvecklare hade inte uppskattat att jag lagt till detta "aber" i klasserna
- Det hade påtvingat en "implicit policy" vid tilläggande av fler, mer sammansatta klasser. Att implementera Equals() för dem är helt onödigt för slutprodukten.
- Alternativ två, som jag var rädd att välja först, verkar efter dessa två timmars huvudbry inte så dumt längre. Det är att helt enkelt bygga specialtester för "de vanligaste klasserna" -- det är trots allt det enda jag kan testa i dagsläget (framtida klasser är svåra att testa!).
Läxa att lära:
Equals() är inte nödvändig för tillstånds-testning!
Läs även andra bloggares åsikter om tdd, geometri, testning, programmering
Att designa för testbarhet
 Jag har lagt mig till med en ny designtumregel.
Jag har lagt mig till med en ny designtumregel.Håller på att läsa "Working Effectively with Legacy Code" av Michael Feathers, det är från den följande insikt bubblat upp:
1. Varje klass ska gå att instansiera utan beroenden, varken interna (att den instansierar/anropar metoder i sina metoder) eller externa (beroende på fil / databas etc.).
2. Om en klass behöver externa / interna beroenden, ska dessa skickas med explicit i konstruktorn
Detta gör enhetstestning av klassen möjlig. Och därmed ökar kvalitén på klassen. Och den här stackars kodaren mår bättre :)
Om man måste använda sig av GUI/Databas och annat grejsimojs, kan man försöka bryta ut "logik" ur den koden till "Santas Little Helper"-klasser som man kan testa istället.
Läs även andra bloggares åsikter om tdd, mjukvaruutveckling, testning, programmering
Böcker jag vill läsa och/eller ha i hyllan
 Working Effectively with Legacy Code (Michael Feathers)
Working Effectively with Legacy Code (Michael Feathers) Refactoring to Patterns (Joshua Kerievsky)
Refactoring to Patterns (Joshua Kerievsky) Programming Pearls (Jon Bentley)
Programming Pearls (Jon Bentley) Mythical Man Month (Frederick Brooks)
Mythical Man Month (Frederick Brooks) Game Programming Gems 2-7 (div.; jag har ettan redan)
Game Programming Gems 2-7 (div.; jag har ettan redan)
Flytta källkodsfiler i SVN+VisualStudio-miljö

 Det är inte superenkelt att flytta filer om man kör VisualStudio och SVN som arkivprogram.
Det är inte superenkelt att flytta filer om man kör VisualStudio och SVN som arkivprogram.Problemet är att Visual Studio's projektfiler innehåller sökvägarna till källkodsfilerna. Alternativet, som storkonkurrenten Eclipse valt, är att det är en 1-1 mappning mellan filsystem och projekt.
Detta gör att det blir hårigt att flytta en källkodsfil som finns med i ett projekt. Här är min nuvarande "algoritm", om någon har ännu smidigare sätt, hojta till!
Jag förutsätter att man vill flytta en fil in i en ny projekt-mapp för att strukturera upp sitt projekt.
I projektroten: A.cs
Vill ha den i: rot\NyMapp\A.cs
- Skapa NyMapp mha. Visual Studio högerklick på projektet
- Stäng av Visual Studio
- Högerklicks-dra A.cs till NyMapp, välj "SVN Move versionen files here" på kontextmenyn
- Starta Visual Studio
- Högerklicka på NyMapp och välj "Add->Existing Item", välj A.cs
Läs även andra bloggares åsikter om svn, tips, visualstudio
Modell för mjukvaruutveckling
Håller på att ta mig igenom en artikel med filosofisk ton som beskriver en modell för utveckling av mjukvara. Författaren ser mjukvaruutveckling som ett spel, i spelteoretisk mening. Intressant!
The end of software engineering
Artikeln har tydligen publicerats i denna vetenskapliga tidsskrift:

The end of software engineering
Artikeln har tydligen publicerats i denna vetenskapliga tidsskrift:
En liten godbit innifrån:
Thus, unlike a rock-climbing trip, a software project has two goals:
* To deliver the system;
* To set up for the next game.
The full evaluation of the project therefore includes, first, whether the system was delivered, and second, to what extent an advantageous position was created for the next game.
These two goals compete for resources. The team can deliver the system more quickly if the system will not have to be extended in the future. (It can deliver the system much, much sooner if bugs will not have to be fixed!) Or, the team can set in place a better software architecture and more training and documentation for their successors at the expense of delaying or even preventing the current delivery.
Jäkligt vist sagt... Ett mjukvaruprojekt har två mål i det mest abstrakta: att ge ett resultat (programmet) i slutet av projektet och efterlämna en källkodsbas som är bra att bygga vidare på! Det är detta som är dilemmat man upplever dagligen som programmerare: kunden vill bara ha så snart som möjligt, och man kan koda ihop skräp snabbt också, men man själv funderar på hur kan kan skriva så enkelt som möjligt, så det går att hantera koden i framtiden...
Thus, unlike a rock-climbing trip, a software project has two goals:
* To deliver the system;
* To set up for the next game.
The full evaluation of the project therefore includes, first, whether the system was delivered, and second, to what extent an advantageous position was created for the next game.
These two goals compete for resources. The team can deliver the system more quickly if the system will not have to be extended in the future. (It can deliver the system much, much sooner if bugs will not have to be fixed!) Or, the team can set in place a better software architecture and more training and documentation for their successors at the expense of delaying or even preventing the current delivery.
Jäkligt vist sagt... Ett mjukvaruprojekt har två mål i det mest abstrakta: att ge ett resultat (programmet) i slutet av projektet och efterlämna en källkodsbas som är bra att bygga vidare på! Det är detta som är dilemmat man upplever dagligen som programmerare: kunden vill bara ha så snart som möjligt, och man kan koda ihop skräp snabbt också, men man själv funderar på hur kan kan skriva så enkelt som möjligt, så det går att hantera koden i framtiden...
Intressant TDD-artikel
En seriöst skriven artikel om erfarenheter hos ett spelbolag som använt TDD en längre tid. Speciellt intressant om "bad practices" t.ex. "functional tests instead of unit tests" och "overly complex tests").
http://www.gamesfromwithin.com/articles/0603/000107.html
Den innehöll den klassiska TDD/Waterfall-kurvan också:
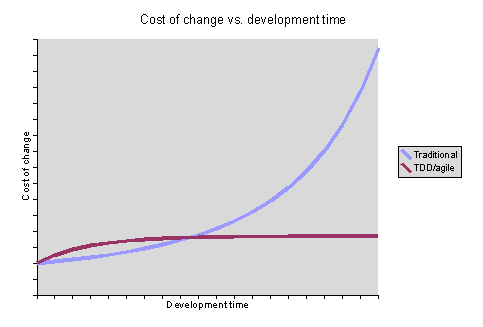
http://www.gamesfromwithin.com/articles/0603/000107.html
Den innehöll den klassiska TDD/Waterfall-kurvan också:
Namngivning: min metod
Jag är mycket känslig för namngivning i källkod. Det kan gå så långt att jag sitter och tänker på namn en halv dag utan att "få något gjort" - eftersom jag inte hittar något ord som passar för begreppet ifråga.
Just av denna anledning, att jag är så känslig för namngivning, försöker jag att "bortse ifrån" namn initialt, när jag löser ett nytt problem. Jag använder helt enkelt det första jag kommer på, för jag är 99% säker på att jag kommer att vara besviken på namnet om någon dag eller två. I och med att refactoring-verktygen i Visual Studio blivit så kraftfulla, är detta ett bekvämt arbetssätt som inte blockerar min utvecklingsinsats, och dessutom ger mig "rätt" namn i slutändan.
Ett problem är fortfarande att publika APIer framförallt i gemensam kod och utilitybibliotek, kan ingå i flera olika solutions, och därmed är refactoring-verktygen verkningslösa. Därför är jag extra försiktig med att lägga till publika APIer i bibliotek - kanske först när koden använts någon månad i aktivt projekt, och känns "stelnad".
För övrigt anser jag att refactoring ska heta faktorisering på svenska! För det är vad det är ..
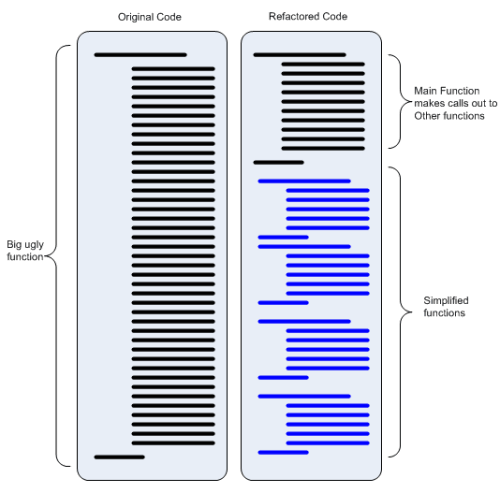
Just av denna anledning, att jag är så känslig för namngivning, försöker jag att "bortse ifrån" namn initialt, när jag löser ett nytt problem. Jag använder helt enkelt det första jag kommer på, för jag är 99% säker på att jag kommer att vara besviken på namnet om någon dag eller två. I och med att refactoring-verktygen i Visual Studio blivit så kraftfulla, är detta ett bekvämt arbetssätt som inte blockerar min utvecklingsinsats, och dessutom ger mig "rätt" namn i slutändan.
Ett problem är fortfarande att publika APIer framförallt i gemensam kod och utilitybibliotek, kan ingå i flera olika solutions, och därmed är refactoring-verktygen verkningslösa. Därför är jag extra försiktig med att lägga till publika APIer i bibliotek - kanske först när koden använts någon månad i aktivt projekt, och känns "stelnad".
För övrigt anser jag att refactoring ska heta faktorisering på svenska! För det är vad det är ..
Lite TDD-spekulation
Funderade på vad som är roligt med tecknade serier idag. Åtminstone en del av humorn ligger i att ta upp människors dubbelmoral; observation av beteenden som strider mot vad människor själva säger ger upphov till en stripp.
Alltså en form av "bevis" på tvetydighet eller motsägelser. Och där finns det en likhet med en upplevelse jag haft av TDD - det tvingar mig att tänka på tvetydigheter i APIer. Det tvingar mer eller mindre fram (mer eller mindre) icke-tvetydiga klasser. Det tvingar mig att tänka på hur klassen ska användas, hur den ska bete sig, hur den inte ska bete sig. Dessa tankegångar har alltid funnits inom mig, men inte stavats eller uttryckts bokstavligen förrän jag kom i kontakt med TDD.
Alltså en form av "bevis" på tvetydighet eller motsägelser. Och där finns det en likhet med en upplevelse jag haft av TDD - det tvingar mig att tänka på tvetydigheter i APIer. Det tvingar mer eller mindre fram (mer eller mindre) icke-tvetydiga klasser. Det tvingar mig att tänka på hur klassen ska användas, hur den ska bete sig, hur den inte ska bete sig. Dessa tankegångar har alltid funnits inom mig, men inte stavats eller uttryckts bokstavligen förrän jag kom i kontakt med TDD.
Ett kort TDD-inlägg
Jag är ett fan av TDD sedan ungefär ett år tillbaka. Men ibland diggar jag det inte; det passar inte allt utvecklingsarbete en programmerare gör vid datorn.
Problemet
Igår ställdes jag inför problemet att försöka sortera ett antal punkt i något slags sick-sack ordning, nerifrån och upp, rad för rad. Algoritmen ska klara att börja i alla fyra hörn av den omslutande boxen kring punkterna, och dessutom "röra sig" antingen horisontellt eller vertikalt. En ytterligare komplikation är att den förutom sicksackmönstret ska klara av att röra sig "radvis" dvs. starta om istället för att "vända" när den påbörjar en nyrad.
Försök till exempel i ASCII-art:
* *
* * *
* *
.. skulle ge, med start i neder vänster hörn, horisontell rörelse och sicksackmönster:
+-->
|__,
>--+
Det är ett ganska inprecist ställt problem och är (tyvärr?) ganska lättlöst för det mänskliga ögat. En förenklande åtgärd är att anta att man alltid börjar i nedervänster hörn och alltid rör sig horisontellt; alla andra fall kan lösas med hjälp av en sådan algoritm plus speglingar/rotationstransformationer av punkterna.
Försök ett
Min kollega och jag diskuterade en "enkel lösning" först av allt. Idén gick ut på att dela upp problemet i en optimeringsdel och en "arbetshäst"; arbetshästen delade upp punkterna i N antal mängder mha. jämnt fördelade linjer från botten till toppen av den omslutande rektangeln. Optimeringsdelen testade sedan alla möjliga sådana delningar för N=3 till 50 eller liknande fixa konstanter, och valde helt enkelt den "orm" som var kortast.
Entusiastisk inför uppgiften satte jag mig och började skissa på olika hjälpklasser jag skulle använda mig av för att implementera algoritmen. Till att börja med ville jag göra klassificeringen av punkterna enkel, och den blir väldigt enkel om man skalar om punkternas y-värden till heltal, i en skala som bestäms med hjälp av N och den omslutande boxen. Det problem som verkade enklast att börja med var också icke-sicksack-mönstret, dvs. radvis ordning. Då slapp jag tänka på exakt när och hur "ormen" skulle vända. Jag byggde tre miniklasser för detta delproblem:
RowByRowOrder: givet en lista med punkter, klassificeras punkterna efter (int)y dvs heltalsdelen på sin y-koordinat och därefter x. Snabbt och lätt alltså.
SupportLine: kunde givet en omslutande rektangel och ett N beräkna ymin, ystep för linjärt positionerade stödlinjer.
Scaler: kunde omvandla från y i världskoordinater till RowByRowOrder-anpassat y.
Att utveckla och få rätt på dessa klasser tog kanske en eftermiddag. De funkade som tänkt, och jag kunde påbörja den omslutande optimeringsdelen.
Käppar i hjulet
Här uppstod problem. Med tex. en 9x3 grid av punkter som var något ojämnt utplacerade, valde optimeringsdelen hellre N=27 än det mer naturliga N=8, något det mänskliga ögat utan vidare såg. Men optimeringsalgoritmen följde endast vad jag bett den om: minimera ormens längd. Den hittade helt enkelt en orm som splittade en punktrippel i två delar, så att ormen kunde ta sig "rakt upp" istället för att röra sig diagonalt till nästa rad. Smart, men inte riktigt vad jag var ute efter.
Så jag började fundera på vad som var en bättre kriterie, var kort inne på minimera N men det är dödfött eftersom det alltid gick att hitta en orm oavsett N. Tredje försöket blev att minska övre gränsen 50 ner till något rimligt, hastade ihop gränsen N = antal punkter / 2, efter som det på något sätt är rimligt att anta att varje rad innehåller åtminstone 2 punkter. Då hittade algoritmen N=12 istället för N=8 i ovan beskrivna exempel.
Alphasort
Det slog mig plöstligt hur jag kunde splitta punkterna med hänsyn taget endast till deras y-värde och ett bra kriterie som löst baseras på två på varandra följande punkters y-koordinat. Jag ska inte avslöja exakt hur, men jag kan säga att den algoritmen kodade jag på mindre än 10 minuter och den ger riktigt övertygande resultat, inte bara i 9x3-fallet utan i alla andra "trovärdiga" fall jag kunnat hitta på! Jag kallade algoritmen Alphasort. Dessutom klarar den både sicksack och rad-för-rad-mönstret utan någon komplicerad logik.
Jag kunde skrota alla tre hjälpklasser och använda min mindre-än-en-kodsida-alphasort. Den utvecklade jag utan TDD medan de övriga utvecklades minutiöst med TDD.
Slutsats
Nå, vad är sensmoralen? Jo det är att prototypning / efterforskning bäst görs INNAN TDD stadiet - jag visste inte vad jag ville ha förrän jag prövat flera metoder.
TDD när man har en klar bild av matematiken i huvudet; efterforskning, prototypkod innan dess!
Problemet
Igår ställdes jag inför problemet att försöka sortera ett antal punkt i något slags sick-sack ordning, nerifrån och upp, rad för rad. Algoritmen ska klara att börja i alla fyra hörn av den omslutande boxen kring punkterna, och dessutom "röra sig" antingen horisontellt eller vertikalt. En ytterligare komplikation är att den förutom sicksackmönstret ska klara av att röra sig "radvis" dvs. starta om istället för att "vända" när den påbörjar en nyrad.
Försök till exempel i ASCII-art:
* *
* * *
* *
.. skulle ge, med start i neder vänster hörn, horisontell rörelse och sicksackmönster:
+-->
|__,
>--+
Det är ett ganska inprecist ställt problem och är (tyvärr?) ganska lättlöst för det mänskliga ögat. En förenklande åtgärd är att anta att man alltid börjar i nedervänster hörn och alltid rör sig horisontellt; alla andra fall kan lösas med hjälp av en sådan algoritm plus speglingar/rotationstransformationer av punkterna.
Försök ett
Min kollega och jag diskuterade en "enkel lösning" först av allt. Idén gick ut på att dela upp problemet i en optimeringsdel och en "arbetshäst"; arbetshästen delade upp punkterna i N antal mängder mha. jämnt fördelade linjer från botten till toppen av den omslutande rektangeln. Optimeringsdelen testade sedan alla möjliga sådana delningar för N=3 till 50 eller liknande fixa konstanter, och valde helt enkelt den "orm" som var kortast.
Entusiastisk inför uppgiften satte jag mig och började skissa på olika hjälpklasser jag skulle använda mig av för att implementera algoritmen. Till att börja med ville jag göra klassificeringen av punkterna enkel, och den blir väldigt enkel om man skalar om punkternas y-värden till heltal, i en skala som bestäms med hjälp av N och den omslutande boxen. Det problem som verkade enklast att börja med var också icke-sicksack-mönstret, dvs. radvis ordning. Då slapp jag tänka på exakt när och hur "ormen" skulle vända. Jag byggde tre miniklasser för detta delproblem:
RowByRowOrder: givet en lista med punkter, klassificeras punkterna efter (int)y dvs heltalsdelen på sin y-koordinat och därefter x. Snabbt och lätt alltså.
SupportLine: kunde givet en omslutande rektangel och ett N beräkna ymin, ystep för linjärt positionerade stödlinjer.
Scaler: kunde omvandla från y i världskoordinater till RowByRowOrder-anpassat y.
Att utveckla och få rätt på dessa klasser tog kanske en eftermiddag. De funkade som tänkt, och jag kunde påbörja den omslutande optimeringsdelen.
Käppar i hjulet
Här uppstod problem. Med tex. en 9x3 grid av punkter som var något ojämnt utplacerade, valde optimeringsdelen hellre N=27 än det mer naturliga N=8, något det mänskliga ögat utan vidare såg. Men optimeringsalgoritmen följde endast vad jag bett den om: minimera ormens längd. Den hittade helt enkelt en orm som splittade en punktrippel i två delar, så att ormen kunde ta sig "rakt upp" istället för att röra sig diagonalt till nästa rad. Smart, men inte riktigt vad jag var ute efter.
Så jag började fundera på vad som var en bättre kriterie, var kort inne på minimera N men det är dödfött eftersom det alltid gick att hitta en orm oavsett N. Tredje försöket blev att minska övre gränsen 50 ner till något rimligt, hastade ihop gränsen N = antal punkter / 2, efter som det på något sätt är rimligt att anta att varje rad innehåller åtminstone 2 punkter. Då hittade algoritmen N=12 istället för N=8 i ovan beskrivna exempel.
Alphasort
Det slog mig plöstligt hur jag kunde splitta punkterna med hänsyn taget endast till deras y-värde och ett bra kriterie som löst baseras på två på varandra följande punkters y-koordinat. Jag ska inte avslöja exakt hur, men jag kan säga att den algoritmen kodade jag på mindre än 10 minuter och den ger riktigt övertygande resultat, inte bara i 9x3-fallet utan i alla andra "trovärdiga" fall jag kunnat hitta på! Jag kallade algoritmen Alphasort. Dessutom klarar den både sicksack och rad-för-rad-mönstret utan någon komplicerad logik.
Jag kunde skrota alla tre hjälpklasser och använda min mindre-än-en-kodsida-alphasort. Den utvecklade jag utan TDD medan de övriga utvecklades minutiöst med TDD.
Slutsats
Nå, vad är sensmoralen? Jo det är att prototypning / efterforskning bäst görs INNAN TDD stadiet - jag visste inte vad jag ville ha förrän jag prövat flera metoder.
TDD när man har en klar bild av matematiken i huvudet; efterforskning, prototypkod innan dess!
Dagens visdomsord
"När du känner att du måste skriva en kommentar, skriv en metod istället"
-Martin Fowler
TDD-mönster: testning av icke-deterministisk algoritm
Det verkar på ytan knivigt att testa en icke-deterministisk algoritm.
Låt oss säga att vi har en algoritm som givet indata Input ska ge ett Result-objekt som svar, där Result-objektet beror på "något icke-deterministiskt".
Detta går att lösa genom "dependency injection" så här:
Plötsligt kan vi testa våran algoritm!
En nackdel med denna teknik är att testkoden blir ganska så "nära" algoritmens implementation, eftersom den i princip måste känna till exakt hur algoritmen kommer fram till sitt svar (i vilken ordning olika val görs i algoritmen beror ju på slumptaltsgeneratorn). Om det är någon som har en bra lösning på detta problem, ge mig tips :)
Låt oss säga att vi har en algoritm som givet indata Input ska ge ett Result-objekt som svar, där Result-objektet beror på "något icke-deterministiskt".
Detta går att lösa genom "dependency injection" så här:
- Skicka med slumptalsgeneratorn till algoritmen, säg Rnd()
- Använd Rnd() i den icke-deterministiska delen av algoritmen
Plötsligt kan vi testa våran algoritm!
En nackdel med denna teknik är att testkoden blir ganska så "nära" algoritmens implementation, eftersom den i princip måste känna till exakt hur algoritmen kommer fram till sitt svar (i vilken ordning olika val görs i algoritmen beror ju på slumptaltsgeneratorn). Om det är någon som har en bra lösning på detta problem, ge mig tips :)
